Strategies to Reduce Downtime During Enterprise Software Upgrades
Enterprise software upgrades are crucial for maintaining competitiveness and security, but they often bring the risk of significant downtime. This disruption can translate into lost revenue, frustrated customers, and damaged productivity. Mastering strategies to minimize this downtime is paramount for any organization relying on robust software systems. This guide delves into the critical planning, implementation, and post-upgrade phases, equipping you with the knowledge to navigate upgrades efficiently and effectively.
From meticulous pre-upgrade planning, including comprehensive data backups and robust communication strategies, to the selection and execution of efficient upgrade techniques like blue-green deployments or rolling upgrades, we explore the key steps involved. We’ll also cover essential post-upgrade monitoring and recovery procedures, ensuring a smooth transition and minimizing any potential disruptions to your business operations. By understanding and implementing these best practices, you can significantly reduce the impact of software upgrades and maintain seamless operations.
Planning & Preparation for Minimized Downtime
Source: ttgtmedia.com
Minimizing downtime during enterprise software upgrades requires meticulous planning and preparation. A well-defined strategy, encompassing thorough testing, robust communication, and a comprehensive rollback plan, is crucial for a smooth transition and minimal disruption to business operations. Ignoring these crucial steps can lead to significant financial losses, reputational damage, and decreased user satisfaction.
Effective planning involves a phased approach, detailed checklists, and proactive communication with all stakeholders. This ensures that the upgrade process is executed efficiently and with minimal unforeseen issues.
Phased Rollout Strategy and Rollback Plan
A phased rollout strategy mitigates risk by allowing for controlled deployment and immediate identification of potential problems. This approach involves deploying the upgrade to a small subset of users or systems initially, followed by gradual expansion to larger groups. For instance, a company might start by upgrading a non-critical department, then move to a less critical department, before finally deploying to the core production systems. This incremental rollout allows for early detection and resolution of issues before they impact the entire user base. A comprehensive rollback plan, detailing the steps required to revert to the previous system version in case of failure, is equally critical. This plan should include clear instructions, tested procedures, and readily available backup data. A recent example of a successful phased rollout is the way Google releases software updates for its products; they test extensively with a limited user base before wider release.
Pre-Upgrade Checklist
A detailed checklist is essential to ensure all necessary steps are completed before the upgrade commences. This checklist should include:
The importance of a comprehensive pre-upgrade checklist cannot be overstated. It acts as a safeguard against overlooked tasks that could lead to unexpected downtime or data loss. The checklist should be reviewed and approved by key stakeholders to ensure its completeness and accuracy.
- Data Backups: Multiple backups of critical data should be created and stored securely in different locations (on-site and off-site) to ensure data recovery in case of failure.
- System Checks: Thorough checks of system resources (CPU, memory, disk space) should be performed to ensure sufficient capacity to handle the upgrade process.
- Network Connectivity: Verify network stability and bandwidth to accommodate increased traffic during and after the upgrade.
- Security Audits: Conduct security audits to identify and address potential vulnerabilities before the upgrade.
- User Communication Plan: Develop and implement a communication plan to inform users about the upgrade, including timelines, potential impacts, and support resources.
Communication Plan
Proactive communication is vital to manage user expectations and minimize disruption. The following table Artikels a sample communication plan:
Clear and timely communication minimizes anxiety and confusion among users during the upgrade process. The plan should include multiple communication channels, such as email, intranet announcements, and possibly even SMS notifications for critical updates.
| Date | Time | Activity | Impact on Users |
|---|---|---|---|
| 2024-10-26 | 10:00 AM | Announcement of upcoming upgrade | Informational email to all users |
| 2024-10-27 | 2:00 PM | Testing in staging environment begins | No impact on users |
| 2024-10-28 | 6:00 PM | Phased rollout to pilot group begins | Limited user group affected |
| 2024-10-29 | 12:00 AM | Full rollout to production environment | Potential brief service interruption (estimated 30 minutes) |
| 2024-10-29 | 1:00 AM | Post-upgrade monitoring and support | Ongoing support available |
Staging Environment Testing
Thorough testing in a staging environment that mirrors the production environment is crucial to identify and resolve potential issues before deployment. This minimizes the risk of unexpected downtime or data loss in the production environment. Different testing methodologies should be employed, including:
Rigorous testing in a staging environment is a critical step to minimize risks and ensure a smooth transition during the software upgrade. This process not only identifies potential issues but also allows for the fine-tuning of the upgrade process before it impacts end-users.
- Unit Testing: Individual components of the software are tested independently.
- Integration Testing: Testing the interaction between different components of the software.
- System Testing: Testing the entire system as a whole to ensure all components work together correctly.
- User Acceptance Testing (UAT): Testing the software with a group of end-users to gather feedback and identify any usability issues.
- Performance Testing: Testing the software’s performance under various load conditions to identify bottlenecks.
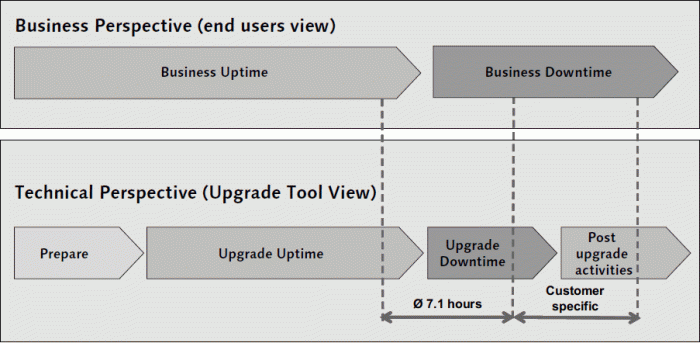
Implementing Efficient Upgrade Techniques

Source: precisely.com
Minimizing downtime during enterprise software upgrades requires a strategic approach that goes beyond meticulous planning. Efficient upgrade techniques are crucial for ensuring business continuity and minimizing disruption to end-users. Selecting the right deployment method and implementing robust monitoring are key components of a successful upgrade strategy.
Upgrade Method Comparison: Blue-Green Deployment, Rolling Upgrades, and Phased Rollouts
Choosing the appropriate upgrade method depends heavily on the complexity of the application, the size of the user base, and the acceptable level of risk. Each approach offers a unique balance between minimizing downtime and managing the inherent complexities of software upgrades.
- Blue-Green Deployment: This method involves maintaining two identical environments: a “blue” (production) and a “green” (staging) environment. The upgrade is performed on the green environment, thoroughly tested, and then traffic is switched from blue to green. Advantages include minimal downtime and easy rollback. Disadvantages include requiring double the infrastructure resources and potential complexities in data synchronization.
- Rolling Upgrades: This approach involves upgrading application instances sequentially, one at a time or in small groups, while maintaining overall system availability. Advantages include reduced downtime and the ability to quickly roll back individual instances if problems arise. Disadvantages include a longer overall upgrade window and increased complexity in managing the upgrade process across multiple instances.
- Phased Rollouts: This strategy involves deploying the upgrade to subsets of users or geographic locations. Advantages include reduced risk exposure, as issues can be identified and addressed in a contained environment before a full rollout. Disadvantages include a longer overall upgrade time and the need for careful management of data consistency across different phases.
Blue-Green Deployment: A Step-by-Step Procedure
A successful blue-green deployment relies on careful planning and execution. The following steps Artikel a typical process:
- Prepare the Green Environment: Deploy the upgraded software to the green environment, replicating the blue environment’s configuration as closely as possible using configuration management tools like Ansible or Puppet. Thorough testing should be performed to ensure functionality and performance meet requirements.
- Data Synchronization: Implement a robust data synchronization strategy to ensure data consistency between the blue and green environments. This may involve techniques like database replication or offline data migration, minimizing data loss or corruption.
- Traffic Switching: Once testing is complete, redirect user traffic from the blue environment to the green environment using a load balancer or DNS configuration. This transition should be performed quickly to minimize downtime.
- Monitoring and Validation: Continuously monitor the green environment for performance and stability after the switch. Ensure key metrics remain within acceptable thresholds.
- Rollback Plan: Have a clear rollback plan in place, readily available to quickly switch back to the blue environment if critical issues are encountered.
Minimizing Database Downtime During Software Upgrades
Database upgrades often represent a significant source of downtime. Strategies for minimizing this downtime include:
- Database Replication: Utilizing database replication allows for performing the upgrade on a secondary replica, minimizing disruption to the primary database. Once the upgrade is complete and validated, the replica can be promoted to the primary database.
- Online Schema Changes: Employ database features that allow for online schema changes, minimizing the need for lengthy downtime. This approach often involves carefully planned alterations that minimize disruption to ongoing transactions.
- Data Migration Tools: Utilize specialized data migration tools that minimize downtime and ensure data integrity during the upgrade process. These tools often provide features for incremental data migration and rollback capabilities.
Real-Time Upgrade Monitoring and Alerting System
A robust monitoring system is critical for identifying and addressing potential issues during an upgrade. This system should include:
- Key Performance Indicators (KPIs): Monitor critical KPIs such as CPU utilization, memory usage, database response times, and network latency. Establish thresholds for each KPI to trigger alerts.
- Real-Time Dashboards: Provide real-time dashboards visualizing the status of the upgrade process and key metrics. This allows for quick identification of any anomalies.
- Alerting System: Implement an alerting system that sends notifications (email, SMS, etc.) to relevant personnel when critical thresholds are breached. This ensures prompt response to potential issues.
Post-Upgrade Monitoring & Recovery
Successful enterprise software upgrades require meticulous post-implementation monitoring and a robust recovery plan. Neglecting this crucial phase can lead to prolonged downtime, data loss, and significant financial repercussions. A comprehensive strategy encompassing proactive checks, contingency planning, and continuous performance monitoring is vital for ensuring business continuity.
Post-upgrade activities should not be considered a mere formality; rather, they represent a critical juncture where potential problems are identified and addressed before they escalate into major disruptions. A well-defined plan will minimize the impact of unforeseen issues and accelerate the return to normal operations.
Post-Upgrade Checklist
A structured checklist ensures all critical aspects of the upgrade are validated. This systematic approach minimizes the risk of overlooking critical details and facilitates prompt identification of any unresolved issues. The checklist should be tailored to the specific software and infrastructure involved but should generally include verification of core functionalities, data integrity, and security configurations. Examples of items to include are: confirmation of successful database migration, validation of user access and permissions, and verification of integration with other systems. A detailed record of each check, including timestamps and outcomes, is essential for future audits and troubleshooting.
Rollback Procedure
A clearly defined rollback procedure is paramount. This plan should detail the steps necessary to revert the system to its pre-upgrade state in the event of unexpected failures or critical errors. This procedure must be thoroughly tested prior to the actual upgrade to ensure its efficacy. The rollback plan should include steps for restoring databases, reverting application code, and restoring system configurations. Consider factors such as data backup frequency and restoration times when designing the procedure. A realistic time estimate for a complete rollback should also be documented. For example, a rollback plan might involve restoring the system from a pre-upgrade snapshot stored on a cloud-based storage service, followed by manual verification of crucial data points.
Key Performance Indicators (KPIs)
Monitoring key performance indicators (KPIs) after the upgrade is critical for assessing system stability and performance. These metrics provide objective data to evaluate the success of the upgrade and identify potential areas needing attention. Regular monitoring allows for early detection of performance degradation or unexpected behavior.
- System Uptime: Tracks the percentage of time the system is operational.
- Transaction Success Rate: Measures the percentage of successful transactions processed by the system.
- Average Response Time: Indicates the average time it takes for the system to respond to user requests.
- Resource Utilization (CPU, Memory, Disk I/O): Monitors the usage of system resources to identify potential bottlenecks.
- Error Rates: Tracks the frequency of errors and exceptions encountered by the system.
Ongoing Maintenance and Support Strategies
Proactive maintenance is crucial for preventing future downtime. This involves a planned and scheduled approach to system maintenance and updates. This includes regular patching, security updates, performance tuning, and capacity planning. Regular backups and disaster recovery drills are essential components of proactive maintenance. Implementing automated monitoring tools and alerts can further enhance the efficiency of maintenance activities. For example, scheduled maintenance windows can be established to apply security patches and perform routine system checks. Automated alerts can be configured to notify administrators of critical events, such as high CPU usage or disk space shortages, allowing for timely intervention and preventing potential issues from escalating.